-
[cs224n] Lecture 8NLP 2021. 8. 7. 23:31
- Machine translation
machine translation이란 말 그대로 특정 언어의 sentence x를 다른 언어의 sentence y로 만드는 task이다.
이번 lecture에서는 시간에 따른 machine translation의 동향에 대해 알아볼 예정이다.
- 1990-2010s: Statistical Machine Translation

다음과 같이, statistical machine translation에서는 주어진 문장에 대해 가장 확률이 높은 문장을 Bayes Rule을 이용하여translation model과 language model의 곱의 최댓값으로 계산한다.
translation model의 경우 단어가 구를 번역하는 역할을 하며, language model은 이전 lecture에서 다룬 LM을 뜻한다.

monolingual data를 이용하는 LM과 달리, Translation Model은 parallel data를 요구하므로 많은 양의 parallel data를 얻는 것이 중요하다.

또한, translation model을 어떻게 학습하는지도 중요한데, 이때 필요한 방법이 alignment이다.
- Alignment

alignment란 parallel data에서 대응되는 단어쌍을 의미한다.
대응 관계는 1:1, N:1, M:N 등이 가능하며 이로 인해 복잡한 양상을 띄게 된다.
대응 관계가 복잡할수록, 인간이 각각의 feature를 생성하여 대응 관계를 매핑하기 어려워진다.
alignment를 학습시킬 좋은 방법이 무엇이 있을까?

첫번째로는 모든 y에 대한 경우의 수를 다 따져보며, 모든 확률을 계산하는 것이다.
하지만 이와 같은 방식은 매우 cost가 높기에, 휴리스틱 알고리즘을 활용하여 너무 낮은 확률들의 경우의 수를 가지치기 하며 높은 확률만 남겨 cost를 줄일 수 있다. 이러한 방식을 decoding이라 칭한다.
이러한 SMT(Statistical Machine Translation)은 굉장히 복잡하며, 사람에 의한 많은 feature engineering이 필요하다.
이러한 한계점을 극복하기 위해 도입된 것이, 예상하다시피 Neural Net을 이용한 Neural Machine translation이다.
- Neural Machine Translation: Sequence to Sequence

Seq2Seq는 다음과 같이 동작한다.
1. word embedding을 이용하여 word를 encoder의 입력단에 입력한다.
2. Encoder RNN은 source sentence의 encoding을 생성한다.
3. 생성한 encoding을 decoder RNN의 initial hidden state로 입력한다.
4. decoder RNN은 encoding에 따라 target word를 생성한다. 이 때 생성하는 단어는 예측 단어의 확률 분포 중 최대 확률을 가지는(argmax) 단어이다.
5. decoder RNN이 END token을 생성하면 문장 생성을 중단한다.

-Seq2Seq는 조건부 LM이다.
LM인 이유: decoder가 target sentence의 다음 단어를 예측하기 때문.
조건부인 이유: SMT와 달리, 예측이 source sentence을 고려하여 생성되기 때문.

Seq2Seq를 Training 하는 방법: decoder RNN의 모든 단계에서 coss entropy를 이용하여 loss를 계산한다.
이를 단계 수로 나누어 최종 loss를 구하며, 최종 loss를 이용한 backpropagation은 전체 시스템에 걸쳐 전파된다.
Seq2Seq는 전체 시스템으로서 최적화되며, 개별적으로 학습하는 것은 좋지 않다고 한다.

각 step마다 가장 높은 확률의 단어를 고르는 것이 현재의 방법이고, 이를 greedy decoding이라 한다.
과연 이러한 방법은 옳은 것이고 문제가 없을까?

- 결정을 내린 것에 대해 돌아갈 방법이 없다는 것이 Greedy decoding의 문제점이다.
즉, 잘못된 단어를 선택하여도 되돌릴 방법이 없으며 이로 인해 잘못된 단어를 이용해 계속하여 단어를 생성해야되는 문제점이 존재한다.
그렇다면 이에 대한 해결책이 무엇이 있을까?


첫번째는 모든 가능한 경우의 수를 계산하는 방식이다. 거듭제곱으로 검색 범위가 넓어지며, 굉장히 큰 cost를 요구한다.
두번째는 k개의 가장 가능성이 높은 번역을 선택하여 가지치기 하는 방식이다. 초반에 살펴본 휴리스틱 알고리즘을 활용한 decoding 방식과 유사한 방식이다.


Greedy decoding / Beam search example Greedy decoding의 경우, END token을 생성할 때까지 단어 생성을 진행한다. 반면, Beam search decoding은 END token을 생성하더라도 다른 가설을 탐색해야 한다. 그러므로 Beam search decoding은 stop point를 지정해줘야 하는데, stop point를 지정하는데 2가지 방법이 있다.
1. 정해진 시간 t에 도달하면 중단한다.
2. n개의 완료된 가설을 생성하면 중단한다.

이렇게 완성된 가설 중 가장 높은 score를 받은 가설을 채택한다. 이때, score는 각각 음수이므로, 문장이 길수록 음수가 더해져 낮은 score를 갖게 된다. 이를 보완하기 위해, score의 합을 전체 timestep 수로 나누어 평균치를 구하여 이를 비교하게 된다.

보다시피, NMT를 이용하면 SMT 에 비해 많은 장점을 갖게 된다.

반면, NMT에도 단점이 존재하는데 바로 blackbox problem이다.
모델의 판단 알고리즘을 이해하기 어려우며, translation에 가이드라인 혹은 특별한 규칙을 추가하는 것이 어렵다.

그리고, Seq2Seq를 이용한 Machine Translation 또한 완벽하지 않아 NMT 분야에 대해 지속적인 연구가 진행중이다.
그러던 중, Seq2Seq에 Attention 개념이 추가되면서, NMT의 성능에 큰 비약이 일어났다.
- Attention
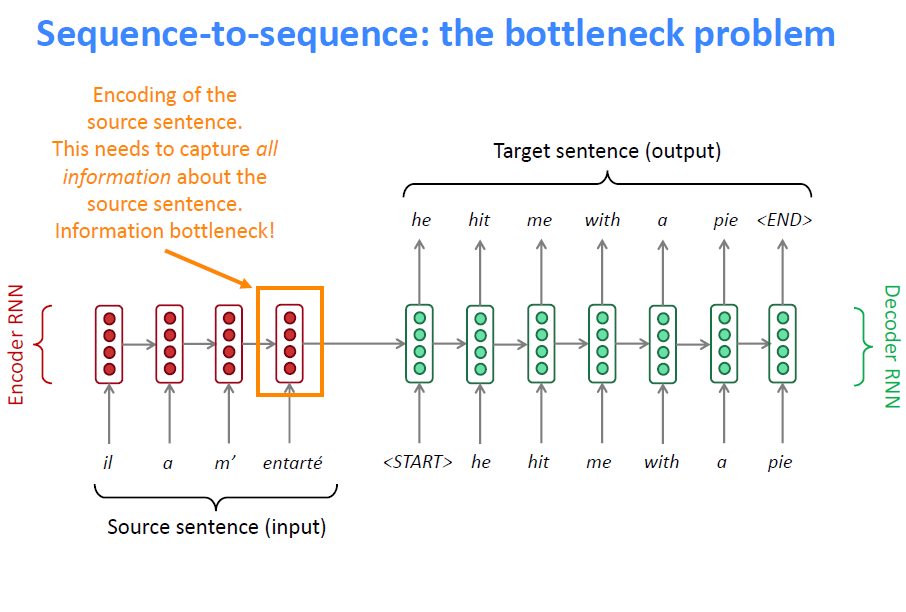
Seq2Seq의 문제점으로, source sentence의 인코딩이 source sentence의 모든 정보를 가지고 있어야 하는 information bottleneck 현상이 거론되었다. 이제 소개할 Attention은 이러한 병목현상을 해결하는 솔루션의 역할을 한다.
Attention의 key idea: on each step of the decoder, use direct connection to the encoder to focus on a particular part of the source sequence

어텐션 스코어란 현재 decoder의 시점 t에서 단어를 예측하기 위해, incoder의 모든 hidden state 각각이 decoder의 현 시점의 hidden state와 얼마나 유사한지를 판단하는 스코어값이다. 어텐션 스코어의 계산은 decoder의 hidden state를 transpose 한 값에 incoder의 hidden state를 내적하여 계산한다.
이렇게 계산한 score에 softmax를 적용하여 확률 분포가 된 Attention distribution을 통해 지금 decoder timestep에서 어느 encoder hidden state에 말 그대로 'Attention'하고 있는지를 확인할 수 있다.

이렇게 계산한 Attention output을 decoder hidden state에 concat한 다음, 이전처럼 확률분포를 계산하게 된다.

지금까지 설명한 내용을 수식으로 표현하면 다음과 같다.

Attention의 효과는 굉장했다!
Attention을 통해 bottleneck problem, vanishing gradient problem의 해결을 도울 뿐 아니라, interpretability도 제공하였다.
attention distribution을 보면서, 우리는 decoder가 어디에 attention 하고 있는지를 알 수 있게 되었다.
즉, alignment를 학습시키지 않았음에도 soft alignment를 얻을 수 있는 것이다.

여기서 value와 query에 대해 눈여겨볼 필요가 있는데, 이후 attention is all you need: transformer에서 이에 대한 개념을 사용하게 되는데, transformer는 어텐션만큼 많은 아키텍쳐에서 사용되는 개념이므로 이에 대해 정의하고 넘어가겠다.
set of vector인 value에 대해 attention은 vector 인 query에 dependent한 weighted sum of the values를 계산하는 기술이다.
이게 무슨말인가 싶을 수 있어 밑에 예시를 들어 설명하겠다.
Seq2Seq + attention 모델에서, 각각의 decoder hidden state는(=query) 모든 encoder hidden states(values)를 attend하는 것이다.
즉, 이전에 attention distribution을 이용하여 현재 decoder timestep에서 어느 encoder hidden state를 'Attention'하고 있는지 알 수 있다는 의미가 곧 이 의미인 것이다.

즉, weighted sum은 values 에 포함되어 있는 정보들에 대한 선택적 요약이며, query는 어떤 values에 집중할지 결정하는 역할을 한다.
여기서 attention과 lstm과 유사점을 알 수 있는데, 바로 모델이 context에 기반하여 어디에서 정보를 가져올지 결정한다는 것이다.

앞서 소개한 attention score를 계산하는 방법외에, 다음과 같이 attention score를 weight matrix 혹은 activation function을 추가하여 계산하는 방법 또한 존재한다.
'NLP' 카테고리의 다른 글
[cs224n] Lecture 7 (0) 2021.08.07 [cs224n] Lecture 6 (0) 2021.08.07 [cs224n] Lecture 5 (0) 2021.08.07 [cs224n] Lecture 4 (0) 2021.08.07