-
[cs224n] Lecture 4NLP 2021. 8. 7. 23:30
- Matrix gradient for Neural Network
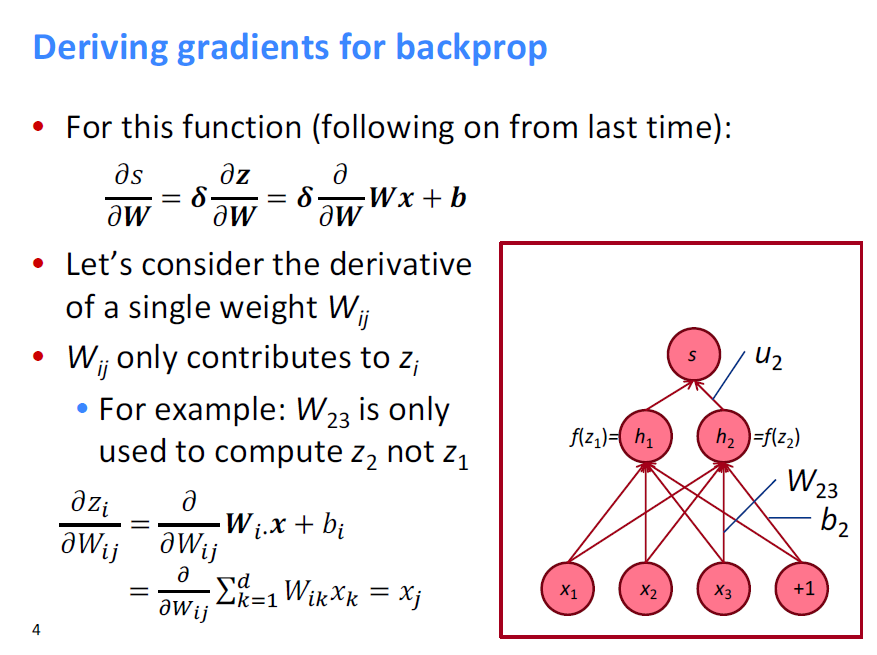
다음과 같이, z를 W(ij)으로 미분한 값은 현재의 Local gradient signal x(j)이다.

즉, s를 W으로 미분한 값은 위에서 내려오는 error 와 현재의 Local gradient signal 을 곱한 값이다.
다시말해, Upstream gradient 과 Local gradient를 곱한 값이 s의 Weight matrix에 대한 미분값이다.(ds/dW)
이 값을 이용하여 Backpropagation 시 가중치를 업데이트 한다.
이와 같이, Upstream gradient 와 Local gradient를 곱한 값을 이용하는 부분은 Lecture 4 후반 부분에 다시 이용된다.

그렇다면 위에서 Error signal을 이용하여 window 내의 word vector들을 업데이트 시킬 수 있지 않을까?
결론부터 말하자면, 가능하다.
실제로 Error signal을 이용하여 word vector들을 업데이트 시킬 수 있고, 이를 이용하여 named entity를 고르는데
효과적인 방향으로 word vector들을 움직일 수 있다.
하지만 이러한 방식에 문제점이 존재하는데,
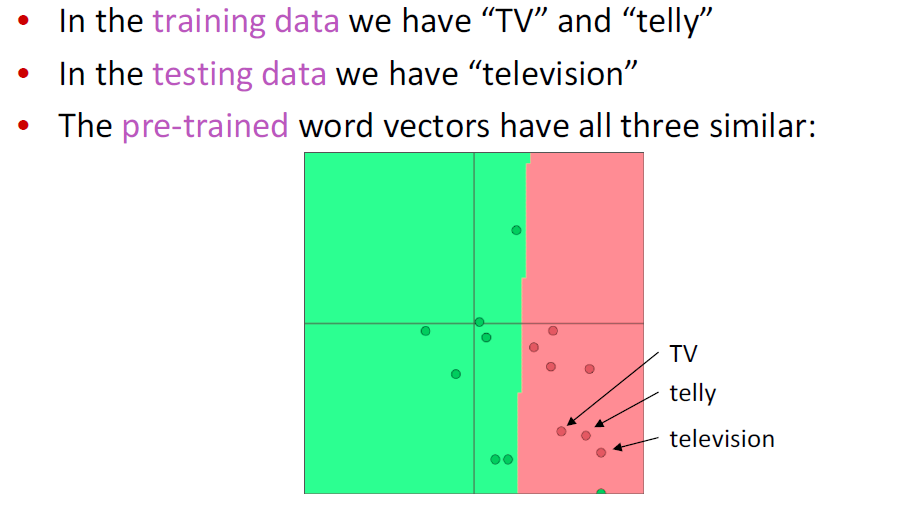
다음과 같은 조건으로 word vector가 존재한다고 가정하자.

Error signal을 이용하여 word vector들을 움직일 경우,
train data에 존재하는 telly 와 tv는 움직이겠지만, television의 경우 그 위치 그대로 유지가 되어
결국 classification에서 아예 다른 단어로 인식할 가능성이 존재한다.
그렇다면 우리는 pre-trained word vector를 freeze하는 것이 정답일까, 혹은 학습시키는 것이 정답일까?
답은, 케바케이다.
만약 우리가 학습할 수 있는 큰 데이터가 있다면, task 수행과 함께 word vector를 fine-tuning하는 것이 좋을 수 있으며
반대로 training set이 작은 경우, word vector를 업데이트 하지 않는 것이 좋다.
- Computation Graphs and Backpropagation
앞서 chain rule을 이용하여 기울기 값을 구한 것을 이용한 것처럼,
여기서는 higher layer에서 계산한 derivatives를 활용하여 lower layer의 derivatives를 계산하는 방법에 대해 학습한다.

먼저 neural net을 따라 결과값까지 계산을 한다. 이를 Forward Propagation이라 칭한다.

이후, 우리가 하고싶은 것은 Backpropagation을 통해 higher layer의 기울기 값을 lower layer에 전달함으로서,
각 layer에서의 기울기 값을 구하는 것이다.

즉, 다음과 같이 각각의 layer에 대해서 독립적인 연산을 진행함으로서, 연산의 중복을 허용하는 것이 아닌
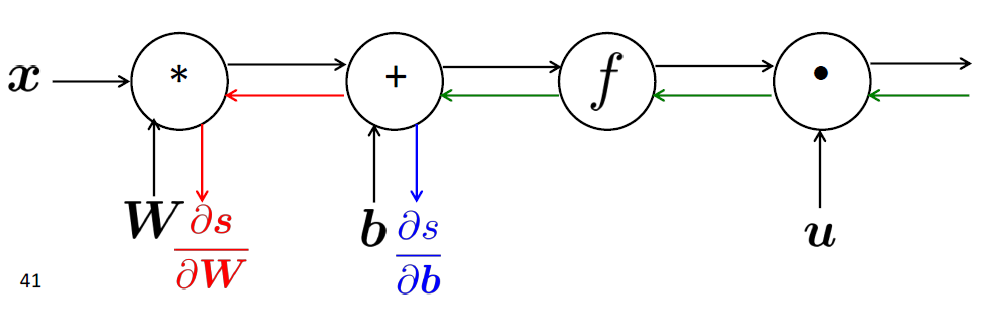
한번의 pass를 통해 모든 layer에 대한 기울기 값을 한번에 계산하는 것을 원하는 것이다.
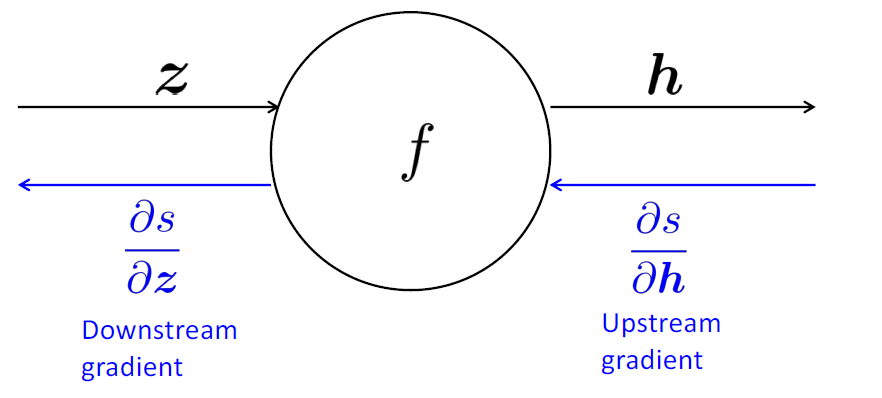
즉, 이를 구현하기 위해서는 각각의 Node들이 upstream gradient(ds/dh)을 받고, downstream gradient(ds/dz)를 전달해주는 방법이 필요하다.
식에서 보다시피, 우리가 dh/dz 값을 알게 된다면, Upstream gradient를 이용하여 Downstream gradient를 계산할 수 있다.

다행히도, dh/dz의 경우 우리가 보유한 수식에서 그 값을 구할 수 있다. (ex: h = f(z))
이러한 값을 local gradient 라 부르며, Downstream gradient는 Upstream gradient와 local gradient의 곱으로 표현할 수 있다.
이후에 다룬 내용은 연산에 따른 gradient의 flow에 관한 내용이다.
간단히 설명하면,

더하기는 upstream gradient를 배분하고
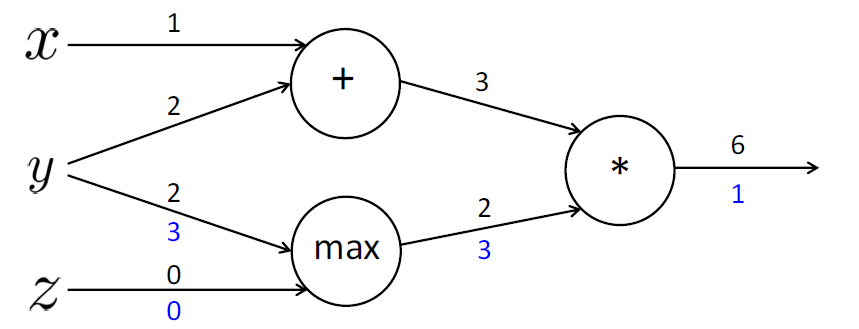
max 는 upstream gradient를 라우팅하며,
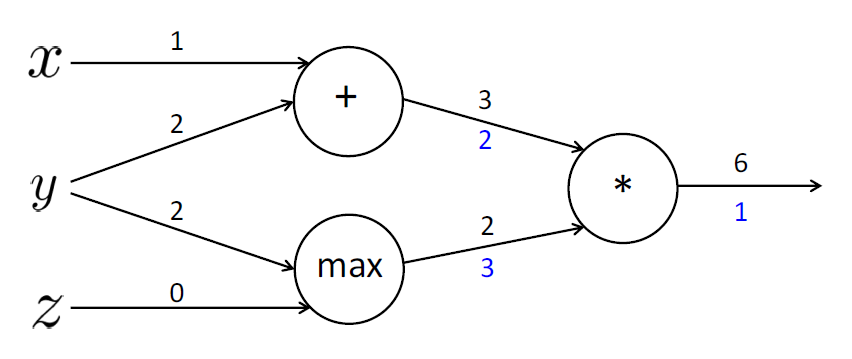
곱하기는 upstream gradient를 스위칭시킨다.
-Computation Graph
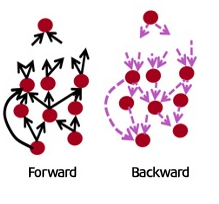
'Computation Graph' 의 의미는 값을 그래프 노드 위에 위치시킨다는 의미이다.
현대의 DL framework들은 그래프 기반의 연산을 진행하며, 그래프 기반의 연산의 경우
Forward 과정과 Backward 과정이 시간복잡도가 동일하게 되므로, 효율적인 연산이 가능하다고 한다.
-Numeric Gradient
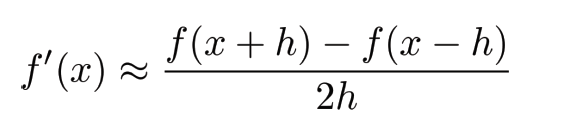
다음과 같이, h에 작은 값을 대입하여 순간 기울기를 구하는 것을 Numeric Gradient라 한다.
이를 통해 기울기 값을 제대로 구했는 지 알 수 있다.
- Technique for Neural Nets
-Overfitting: By Regularization
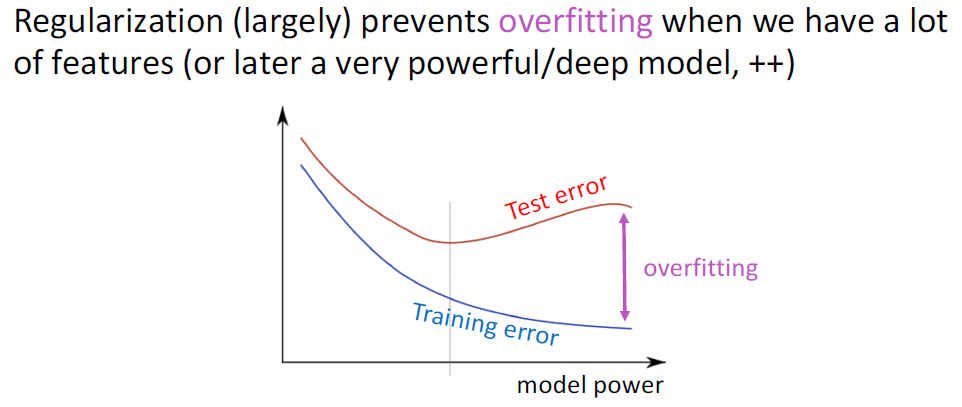
학습을 진행하다 보면, 모델은 Loss값이 최소가 되도록 모델의 파라미터 개수를 늘리며 고차원의 모델을 형성하게 된다.
차원이 높아질수록 현재 학습하고 있는 Training Set에 과적합하게 된다.
이를 방지하기 위해 모델이 복잡해질수록, 즉 파라미터 개수가 많아질수록 패널티를 부과한다.

다음과 같이 Loss function에 패널티 항을 추가함으로서, Overfitting 문제를 해결하는 방법이 Regularization이다.
-Vectorization
간단히 말해, 'loop를 이용해 벡터끼리의 연산을 진행하기보단 matrix로 벡터들을 concat시킨 후 연산하는 것이
훨씬 빠르다' 라는 내용이다.
-activation function

activation function으로 먼저 소개된 것은 sigmoid와 tanh이다.
수업의 내용대로, sigmoid는 Neural Net의 초기 개발에 많이 사용되었으며,
현재는 0과 1의 gate를 생성하는 경우를 제외하고는 잘 사용하지 않는다.
최신 모델에서 사용되지 않는 가장 큰 이유는 Gradient Vanishing 문제인데,
이는 이후의 Lecture에서 좀 더 자세히 다룰 예정이다.
tanh의 경우 많은 모델에서 activation function으로 사용되고 있으며,
흥미로운 점은 tanh은 sigmoid 함수를 움직이고 rescaling하여 만든 함수라는 것이다.
sigmoid와 마찬가지로 최신 모델에서 default로 사용되는 activation function은 아니다.
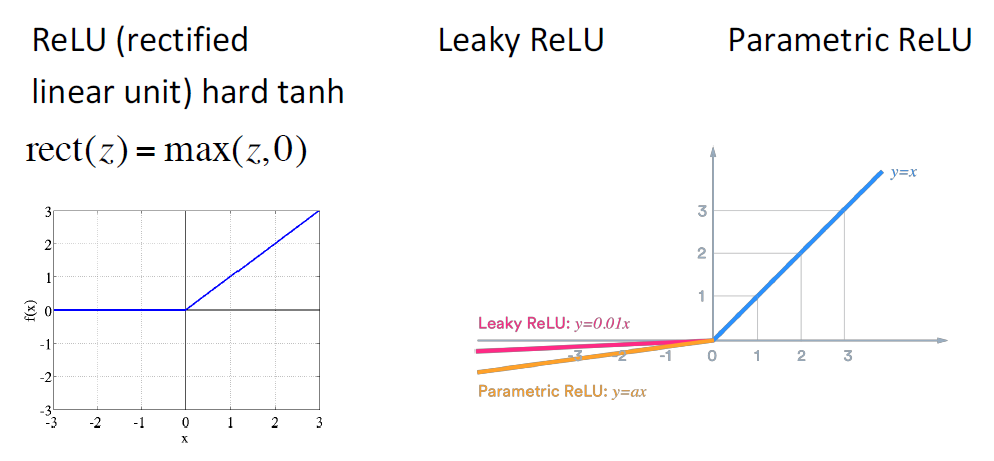
최신 모델에서 가장 많이 사용되는 activation function은 ReLU 혹은 이의 변형이며,
언뜻 보기엔 단순한 함수이기에 최신 모델에서 자주 사용되는 이유에 대해 의문이 생길 수 있다.
ReLU의 장점은 기울기 값이 1이기에 학습 속도가 빠르며, 앞서 소개된 sigmoid나 tanh와 달리
gradient vanishing 문제의 해결에 큰 기여를 할 수 있다.
반면 ReLU에도 문제점이 존재하는데, 어떤 뉴런에서든 음수값이 들어오게 되면 Backpropagtion 시
기울기 값이 0이 되며 해당 노드가 다 죽어버리는 문제가 생기며 이를 Dying ReLU라 한다.
하지만 Dying ReLU가 Neural Net에서 강점으로 작용하는데, 이에 대해서는 향후 자세히 포스팅 할 예정이다.
(여기는 cs224n Lecture 노트이므로..)
여하튼 Dying ReLU를 해결하기 위해 나온 activation function이 Leacky ReLU이며
위의 사진에서 확인할 수 있듯, 음수값이 들어오게 돼도 미분값이 0이 되지 않은 ReLU와 유사한 함수이다.
'NLP' 카테고리의 다른 글
[cs224n] Lecture 8 (1) 2021.08.07 [cs224n] Lecture 7 (0) 2021.08.07 [cs224n] Lecture 6 (0) 2021.08.07 [cs224n] Lecture 5 (0) 2021.08.07