-
[cs224n] Lecture 6NLP 2021. 8. 7. 23:30
- Language Modeling
Language modeling의 정의: Language modeling is the task of predicting what word comes next.
More formally, given a sequence of words x(1)...x(t), compute the probability distribution of the next word x(t+1)
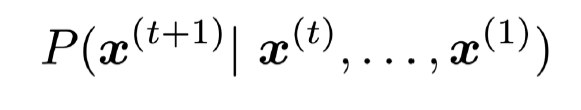
즉, 만약 x(1)부터 x(T)까지의 text가 존재한다면, Language model에 따른 이 text의 확률은 다음과 같다.

그렇다면, 우리는 현재 존재하는 text를 이용하여 어떻게 다음 text의 확률을 계산할 수 있을까?
설명을 위해, 먼저 n-gram의 개념에 대해 알고 넘어가자.
n-gram의 정의는 a chunk of n consecutive words이다. 즉, 연속된 n개의 단어 덩어리를 뜻한다.
또한, 설명을 위해 가정 하나를 하는데, 바로 다음 단어는 오직 직전의 n-1개의 단어에만 영향을 받는다는 것이다.
이를 수식으로 표현하면 다음과 같다.
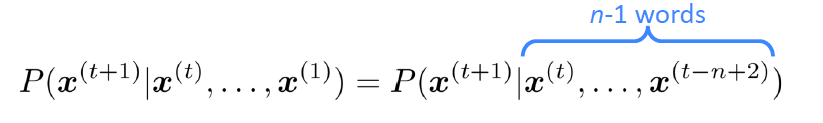
그러면 이제 설명을 위한 선행조건이 완료되었다...
위에서 설명한 n-gram과 가정을 활용하면,
우리가 구하고 싶은 현재 text에 대한 다음 text의 확률은 P(n-gram)/P((n-1)-gram)으로 나타낼 수 있다.
즉, 이를 수식으로 표현하면 다음과 같다.
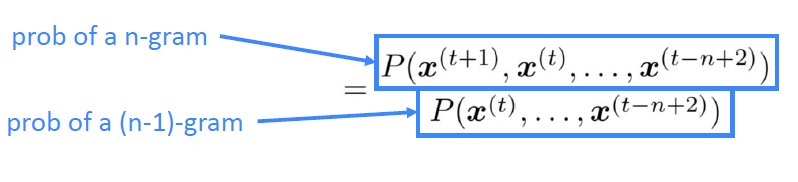
n-gram의 확률을 counting을 통해 통계적 근사를 하게 된다면, 이 식은 다음과 같이 변형될 수 있다.
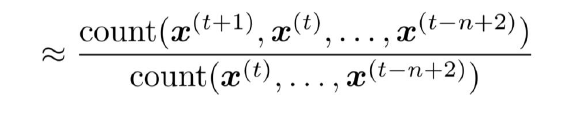
즉, 우리는 현재로부터 이전의 n-1개의 word의 출현 빈도를 카운팅함으로서, 다음 단어에 대한 확률을 계산할 수 있다.
이러한 n-gram LM을 이용하여 text generating이 가능하다.


하지만 이러한 n-gram LM에 문제점이 존재한다.
1. Sparsity Problem
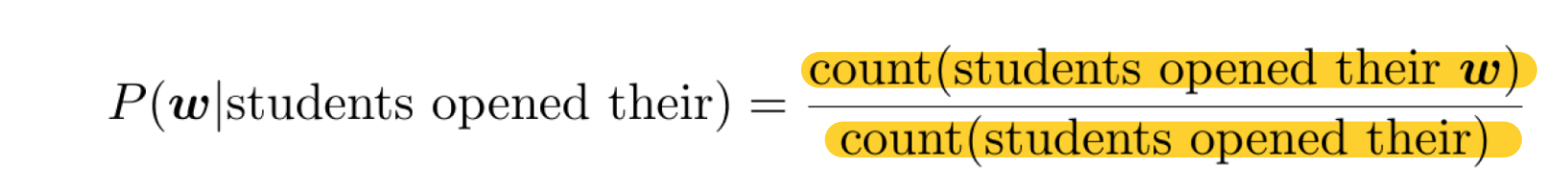
1.1) 분자의 등장 횟수가 0일 경우, 확률값이 0이 된다.
-> 모든 w에 대해 작은 확률값을 기본 값으로 주어, 확률값이 0이 되는 일이 없도록 한다.
이를 smoothing이라 한다.
1.2) 분모의 등장 횟수가 0일 경우, 확률값을 계산할 수 없게 된다.
-> 이러한 경우, 카운팅하는 단어의 갯수를 하나 줄여 계산을 한다. 즉, n-gram 대신 (n-1)-gram을 사용하는 것이다.
위의 경우, 분모는 count(opened their)가 된다.
이를 backoff라 칭한다.
2. Storage Problem

n을 늘릴수록, n-gram의 count를 저장하기 위해 model size가 커지게 된다.
3. Incoherence Problem
N-gram 모델의 가정은 다음 단어는 오직 직전의 n-1개의 단어에만 영향을 받는다는 것이다.
n의 size가 작을 경우, 문맥을 제대로 반영하지 못해 중요한 정보를 놓치고 올바른 예측을 할 수 없게 된다.
-Conclusion
N-gram Language Model은 n이 클 경우, model size가 비약적으로 커지는 Storage Problem을 가지게 되며
n이 작을 경우, 문맥을 제대로 반영하지 못해 중요한 정보를 놓쳐 올바른 예측을 할 수 없는 Incoherence Problem을 갖게 된다.
즉, n을 어떻게 하든 문제가 발생하게 된다.
이러한 문제를 해결하기 위해 Neural Net을 도입하여 문제 해결을 시도하였다.
- Neural Language Model
Lecture 3에서 사용한 Named Entity Recognition과 같이, window-based neural model을 도입하는 것을 생각해볼 수 있다.
다만 NER과 달리, 이번에는 N-gram과 같이 예측할 단어 이전의 n-1개의 단어를 window로 이용할 것이다.
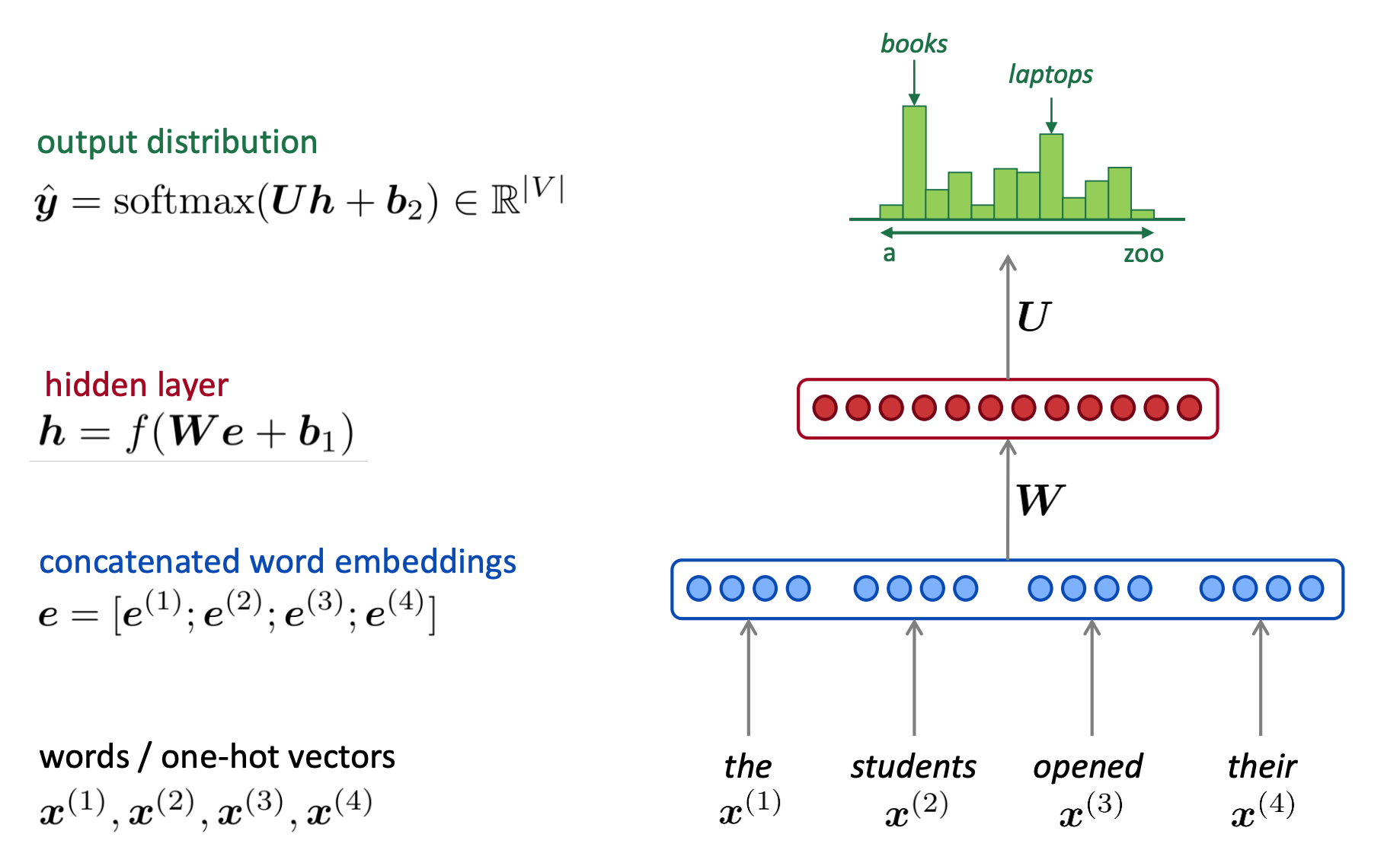
1. 다음 단어를 예측하기 위해 window size의 개수만큼 이전의 단어를 input으로 받는다.
2. 이 단어들을 one-hot vector로 표현한 뒤, Embedding Table을 이용하여 각 단어에 대한 embedding을 lookup 한후, concat한다.
3. concat된 word embedding이 hidden layer와 output layer, 마지막으로 softmax를 거쳐 다음 단어에 대한 확률값으로 출력된다.
마지막 단계에서 softmax를 거쳐 다음 단어에 대한 확률값으로 출력되는 부분에 대해 의문점이 존재했는데,
cross entropy 계산을 편하게 하기 위해 모든 단어들을 sparse representation으로 표현한 것 까지는 이해했지만
이렇게 함으로서 마지막에 곱해지는 행렬의 크기가 매우 커짐을 예측해볼 수 있다.
즉, loss 계산을 단순화하기 위해 sparse representation을 사용하면 matrix의 크기가 비약적으로 커지게 되는데, 이것이 과연 성능의 향상을 이끌어낼 수 있냐는 것이다.
이에 대해 의문점을 가지면서 쭉 lecture를 들었는데, 역시 스탠포드 교수님답게 이에 대해 lecture 9에서 상세히 다루었다.
위의 궁금점은 Lecture 9에서 상세히 다룰 예정이다.
Neural Language Model's improvement & limitation
improvement -sparsity problem과 storage problem을 해결하였다.
limitation - 작은 window size와 window size를 늘리더라도, 중요한 context를 놓칠 가능성이 존재함.
즉, Neural Language Model은 N-gram Language Model의 문제점을 상당히 해결하였지만, 아직 window size에 따른 한계점이 존재하였다.
결국 input의 길이에 상관없이 모든 input을 이용할 수 있는 neural 아키텍쳐의 필요성을 느끼게 되었고, 이로 인해 RNN이 탄생하였다.
- RNN(Recurrent Neural Network)
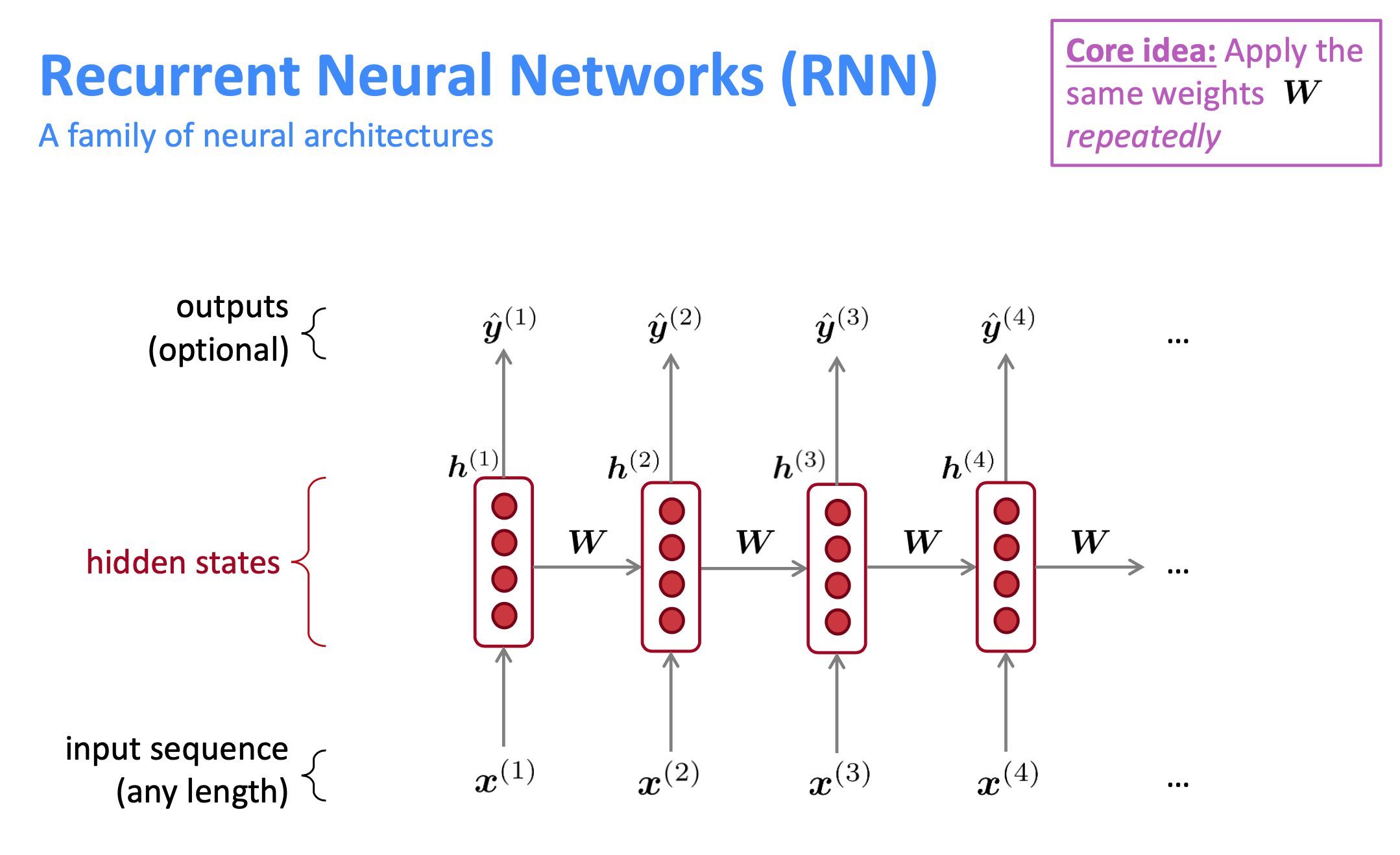
RNN의 핵심 아이디어는 같은 가중치 W값을 반복적으로 사용하는 것입니다. 그러한 이유로 Recurrent라는 이름이 붙게 되었습니다.
RNN의 특징은 기존 신경망의 구조와 달리, 하나의 state값이 이전의 input들에 영향을 받는다는 점이다.
이러한 이유로 RNN은 문장의 context를 이용하여 현재 state 값을 계산할 수 있다.
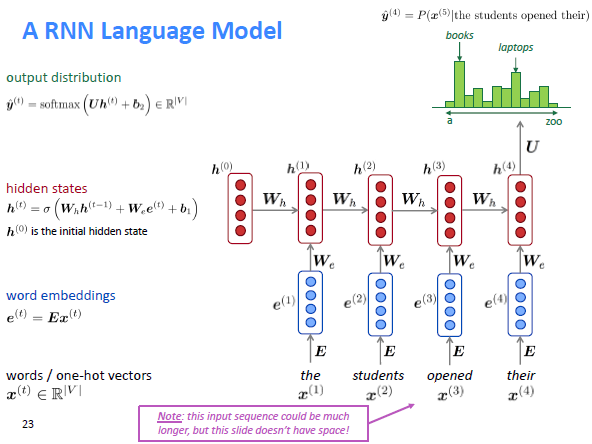
다음 사진은 RNN와 이전에 소개한 Neural language model을 비교한 것이다.
가장 큰 차이점은 hidden state/layers 인데, RNN의 경우 각 word들을 임베딩 후, sequence에 맞게 hidden state에 입력한다. 반면, Neural LM은 모든 word들을 임베딩하여 이들을 concat한 뒤, 한번에 입력하는 방식이다.
RNN은 이와 같은 구조를 통해 모든 입력 길이를 처리할 수 있으며, 또한 현재 hidden state를 계산하는데 이전의 input들을 사용함으로서 이전의 입력 데이터에 존재하는 주요한 정보 또한 이용 가능한 장점을 갖게 된다.
RNN의 장점과 단점
-장점
RNN은 인풋 길이에 상관없이 동일한 모델 길이를 유지할 수 있으므로, 높은 확장 가능성을 지니고 있다. 또한, 모든 구간에서 동일한 가중치를 사용하기에, input이 처리되는 과정에서 symmetry가 존재한다.
여기서 동일한 W를 사용하는 것이 성능의 향상을 이끌어낼 수 있는지에 대해 의문이 생길 수 있는데, 수업에서 이에 대한 질문에 짧게 다루었다. 답변은 동일한 W를 사용함으로서, general representation of language and context를 학습할 수 있다고 하였다. 즉, 간단히 말해 개별의 단어에 맞는 가중치를 학습하는 것이 아닌 보편적인 가중치를 학습하기 위해 동일한 W를 사용한다고 할 수 있다.
-단점
Recurrent computation은 이전 hidden state가 계산되어야 현재 hidden state를 계산할 수 있는 구조이기에, 병렬적인 연산이 불가능하다. 컴퓨터의 연산에서 병렬 연산이 불가능하다는 점은 큰 성능 하락을 유발할 수 있다.
RNN은 Vanishing gradient problem을 가지고 있다. 이에 대해서는 이후 lecture에서 서술할 예정이다.
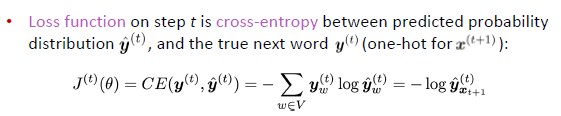
step t에서의 loss function은 위의 식과 같으며, 정답 외의 모든 값들은 0이므로 loss function은 -log(predicted probability)라 할 수 있다.
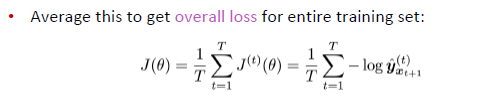
또한 전체 training set에 대해, loss function은 위의 식과 같이 나타낼 수 있다.
하지만 전체 training set에 대해 loss function을 구하여 이용하는 것은 매우 cost가 높으므로, 문장 혹은 문서 단위로 나누어 입력을 주기도 한다. 이러한 경우, 전체적인 계산의 cost는 낮출 수 있지만 이전 문장 혹은 문서의 context를 잃게 되는 문제가 발생한다.
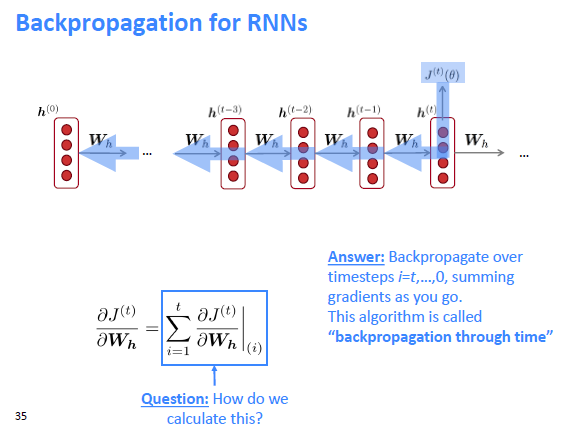
RNN에서 Backpropagation을 할 때, 각 스텝마다 파라미터들이 공유되기 때문에 기존의 backpropagation을 그대로 사용할 수 없다. 대신 Backpropagation through time(BPTT) 라는 변형된 알고리즘을 이용하여 이전 timestep의 gradient를 summing하여 현재 timestep의 gradient를 계산하는데, 그 이유는 특정 hidden state의 기울기 값은 이전 hidden state들의 기울기 값에 의존하기 때문이다.
이에 대해서는 다음 lecture에서 좀더 상세히 설명할 예정이다.
'NLP' 카테고리의 다른 글
[cs224n] Lecture 8 (1) 2021.08.07 [cs224n] Lecture 7 (0) 2021.08.07 [cs224n] Lecture 5 (0) 2021.08.07 [cs224n] Lecture 4 (0) 2021.08.07