-
[cs224n] Lecture 5NLP 2021. 8. 7. 23:30
- Constituency Parsing & Dependency Parsing
Parsing 이란 문장 혹은 구문을 분석하는 방법을 칭하며,크게 Constituency Parsing 과 Dependency Parsing으로 나뉜다.

-Constituency Parsing: 문장의 구성 요소(명사, 동사..)를 이용하여 구조를 분석하는 방법
흔히 우리가 영어 문법을 배울때 사용하는 방식이다.
하지만 문장의 구성 요소만으로는 문장을 올바르게 분석하기가 어려운데, 수업 중 소개한 여러 재미있는 예제들 중
재미있는 예제를 하나 가져와봤다.

(우주에 있는 고래가 귀엽다 ㅋㅋ) 즉, 문장의 구성 요소만으로는 문장을 완벽히 분석할 수 없으며, 단어간의 관계를 파악해야 올바른 분석이 가능하다.
이처럼 단어간의 의존관계를 이용한 Parsing을 Dependency Parsing이라 칭한다.

-Dependency Parsing: 의존관계를 이용하여 구조를 분석하는 방법
수식을 하는 단어를 'head'라 칭하며, 수식을 받는 단어를 'dependent'라 칭한다.

Dependency Parsing은 첫 사진처럼 tree형태로 표현이 가능하지만, 위의 사진과 같이
sequence의 형태로도 표현이 가능하다.
단, sequence와 tree 형태 모두 동일한 output을 가져야한다.
Dependency Parsing을 sequence의 형태로 표현할 경우 제약조건은 다음과 같다.
1. ROOT라는 노드를 문장 맨 앞에 삽입한다.
2. head를 화살표 시작으로, dependent를 화살표를 받는 쪽으로 설정하며 모든 단어가 1개의 dependent를 가지도록 한다.
3. 최종 head를 ROOT로 하며, 모든 수식 관계는 cycle을 형성하지 않고 중복 관계 또한 허용하지 않는다.
이러한 제약 덕분에, sequence로 표현한 dependency parsing을 tree형태로도 표현이 가능하다.
Dependency Parsing에는 크게 4종류가 존재하는데, 이 강의에서는 Transition Based parsing에 집중하여 설명한다.
-Transition Based Parsing

-Transition Based Parsing은 두 단어의 의존 관계를 파악하면서 점진적인 dependency parsing을 구성하는 방식이다.
이러한 방법은 문장을 순차적으로 입력하게 되며, 모든 의존 관계를 분석하지는 못한다.
따라서 속도는 빠르지만, 높은 정확도를 기대할 수 없다.
transition based parsing 에서는 크게 BUFFER, STACK, Set of Arcs 라는 3가지 구조를 가지고 있다.
이름 그대로
1. BUFFER는 문장 sequence를 임시로 저장하는 공간이며,
2. STACK은 BUFFER로부터 온 데이터를 push하거나, decision에 따라 pop하며
STACK 내부 데이터 간의 의존관계를 형성하는 공간을 제공하며
3. Set of Arcs는 parsing의 결과물이 담기게 된다.
BUFFER에서 STACK으로 데이터가 이동하는 과정은 문장의 순서를 따르며, 문장의 순서에 따라
STACK에 push된 데이터들은 기존 STACK 내부의 데이터와 어떤 'state'를 갖게 된다.
parsing 알고리즘은 이 'state'에 따라 decision을 갖게 되며, 총 3가지의 decision이 있다.
1. Shift: BUFFER에서 STACK으로 데이터를 이동
2. Left-Arc: 좌측으로 dependency가 형성된다.
3. Right-Arc: 우측으로 dependency가 형성된다.
이후 lecture에서는 'state'에 따른 decision을 갖게하는 Neural Net을 소개한다.
-Dependency Parsing with Neural Nets

먼저 Neural Net의 input으로 들어가는 feature은 총 3가지이다.
1. words
2. POS
3. dep
흥미로운 점은, word와 마찬가지로 POS(part of speech tag)와 dependency 또한 임베딩하여 활용한다는 것이다.
수업에서는 이를 통해 유사하거나, 반대되는 POS의 특징을 활용할 수 있다고 한다.
이때 수업을 들으며 궁금했던 점은, 결국 dependency를 구성하기 위해 이러한 모델을 개발한 것인데 어떻게 dependency를 input으로 활용할 수 있냐는 것이었다.
그래서 lecture 5에 대한 리뷰 글을 찾아봤는데, lecture 5 리뷰 글은 많았지만 정작 이에 대해 다룬 글은 없었다(...)
좀 더 구글링해 본 결과, input dependency는 이전에 계산한 의존관계라는 것을 알게 되었다.
즉, 이전에 계산한 의존관계를 이용하여 현재의 의존관계를 계산하는 것이었다.

이후, 위에서 설명한 3개의 feature들을 concat하여 모델의 input으로 사용한다.
hidden layer, output layer를 거친 후 softmax를 통해 현재 'state'에 맞는 decision의 확률을 출력한다.
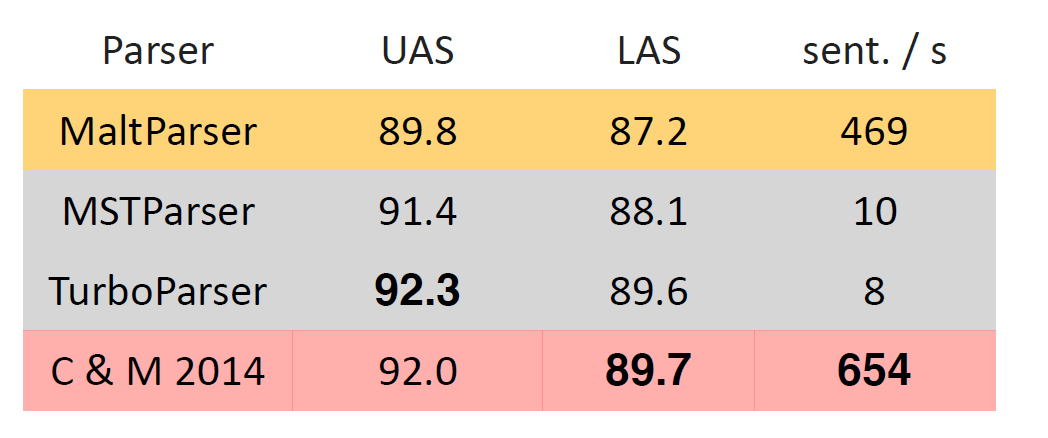
결과를 분석하자면, Graph-Based parser인 turboParser가 Unlabeled attachment score에서는 조금 더 나은 성능을 보였지만, 훨씬 빠른 속도를 확보할 수 있었으며 Labeled attachment score에서는 가장 좋은 성능을 보여주었다.
즉, Neural Nets을 이용하여 빠르고, 좋은 성능을 이끌어낼 수 있었다.
'NLP' 카테고리의 다른 글
[cs224n] Lecture 8 (1) 2021.08.07 [cs224n] Lecture 7 (0) 2021.08.07 [cs224n] Lecture 6 (0) 2021.08.07 [cs224n] Lecture 4 (0) 2021.08.07