-
[cs224n] Lecture 7NLP 2021. 8. 7. 23:30
- Backpropagation for RNN

먼저, 위의 예제를 확인해보자. 다음의 미분값을 어떻게 구할 수 있을까?
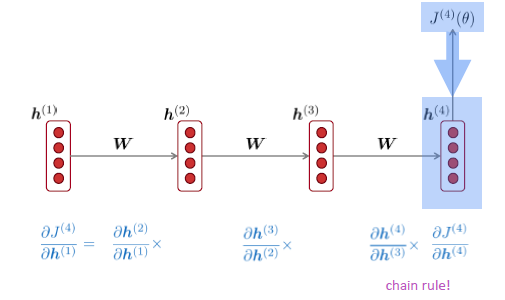
위의 식은 chain rule에 따라 다음과 같이 변형할 수 있으며, 모든 layer에 대해 동일한 가중치를 공유하므로 dh(t)/dh(t-1)은 다음과 같이 하나의 식으로 표현될 수 있다.
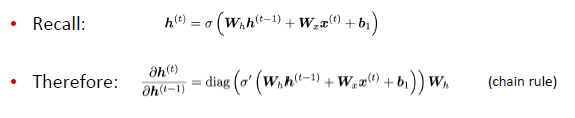
즉, step i에서의 loss J에 대한 미분 값을 이전의 previous step j에 대해 표현하면 다음과 같이 표현할 수 있다.

또한 이 식은 norm의 성질에 의해 다음과 같은 부등식으로 표현할 수 있다.

다음과 같은 부등식을 이용하여, W(h)의 가장 큰 고윳값이 1보다 작다면 계속하여 1보다 작은 값을 곱하기 때문에 gradient가 빠르게 사라지는 vanishing gradient problem이 발생하는 것과, 가장 큰 고윳값이 1보다 크다면 계속하여 1보다 큰 값을 곱하기 때문에 gradient가 빠르게 상승하는 gradient exploding problem이 발생하는 것을 알아낼 수 있다.
-Why is vanishing gradient a problem?

풀어 설명하자면, 멀리 있는 gradient가 근처의 gradient보다 훨씬 작기때문에, 현재 state의 파라미터들이 near effect에 의해서만 업데이트 되며, long-term effect들은 파라미터의 업데이트에 영향을 주지 못한다는 것이다.

또한 gradient 값이 매우 작아져서 소실되어버리는 경우, 정말로 step t 와 step (t+n)이 관계가 없어 gradient 값이 소실된 것인지, 혹은 파라미터가 잘못 설정되어 step t 와 step (t+n)의 dependency를 얻을 수 없는 것인지 알수가 없다는 것이 vanishing gradient의 또다른 문제점이다.

RNN의 vanishing gradient에 따른 문제점 - Gradient exploding

vanishing gradient 외에, exploding gradient 문제 또한 존재한다.
exploding gradient란 gradient값이 너무 커 움직이는 stride가 넓어 loss 값이 수렴하지 않고, 최악의 경우 loss값이 발산하는 경우를 말한다.
하지만 exploding gradient는 vanishing gradient와 달리, gradient clipping으로 간단히 해결할 수 있다.
- Gradient clipping

gradient가 일정 threshold를 넘어가면, SGD update를 적용하기 전에 scale down하는 방법이다.
이를 통해 gradient descent가 큰 step을 갖게 되는 것을 방지할 수 있다.
그렇다면 RNN의 문제점 중 exploding gradient는 해결할 수 있다. 하지만 vanishing gradient 문제는 어떻게 해결할 수 있을까?
바로 RNN에 독립적인 메모리를 부여하는 방법이다.
- LSTM(Long Short-Term Memory)
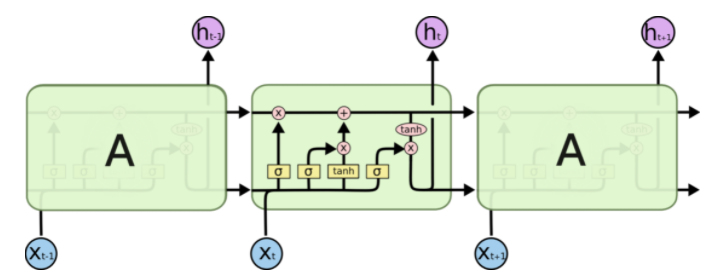
RNN의 vanishing gradient problem으로 인한 long-term dependency problem을 해결하기 위해 RNN에 독립적인 메모리를 부여함으로서 이전의 데이터도 함께 고려하여 output을 만들어내는 모델이다.
LSTM의 key idea
- cell state를 이용한 독립적인 메모리의 구현
- 과거의 정보와 현재의 정보를 이용하여 cell state를 업데이트하고 이를 활용함으로서, 지속적으로 과거의 정보를 이용하도록 구현

-cell은 long-term 정보를 저장하며, hidden state와 cell state를 이용하여 정보를 지우거나, 쓰고, 읽을 수 있다.
-어떤 정보를 지우거나, 쓰고, 읽을지에 대한 선택은 3개의 gate에 의해 결정된다.
-gate 또한 길이 n의 vector이며, gate들의 원소들은 각각 열리거나, 닫히거나, 혹은 그 사이에 있을 수 있다.

위에서 언급한 3개의 gate는 forget gate, input gate, output gate이다.
1. forget gate: 어떤 정보를 잊고 어떤 정보를 기억할지 결정하는 gate이다.
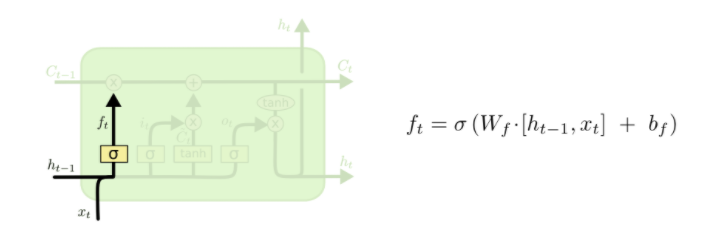
2. input gate: 어떤 새로운 정보를 cell state에 저장할지 결정하는 gate이다.
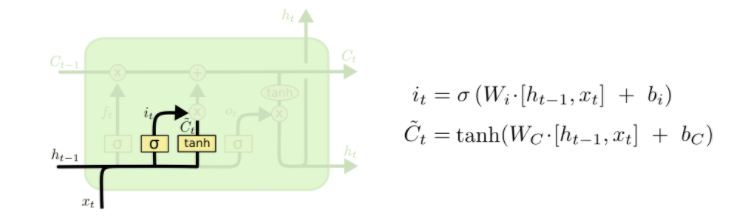
3. output gate: cell의 어떤 부분을 hidden state로 출력할지 결정하는 gate이다.

위의 3가지 gate 모두 sigmoid 함수를 붙인것을 확인할 수 있는데, 이러한 이유는 각 gate의 역할에 맞게 정보를 잊거나/쓰거나/출력할지를 결정하는 역할을 수행하기 위해서이다.
ex) output gate o(t): cell state의 어느 부분을 출력할 지 결정하는 역할을 수행한다.
- Cell state
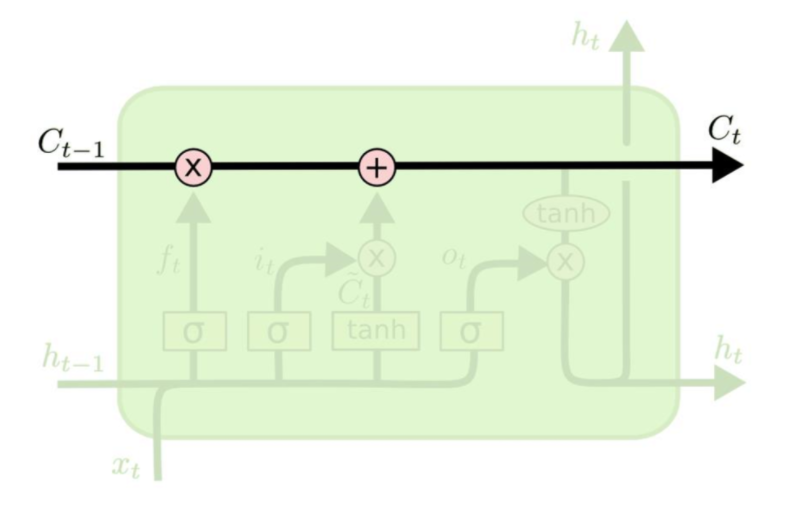
RNN에서 메모리의 역할을 하며, hidden state와 cell state를 이용하여 정보를 지우거나, 쓰고, 읽을 수 있다.
-Update cell state

과거의 정보를 잊을지, 유지할지는 forget gate를 이용하여 계산하고 여기에 cell에 저장할 새로운 정보를 input gate를 이용해 추가하여 cell state를 업데이트한다.
LSTM의 전체적인 도식도는 다음과 같다.
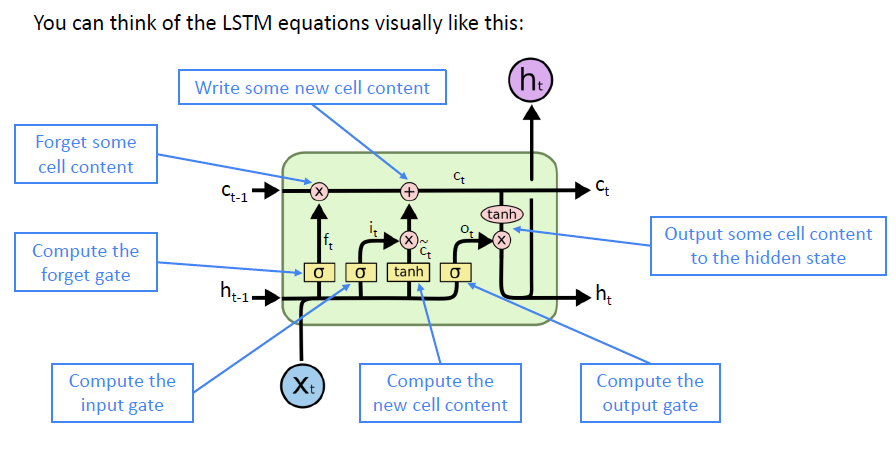
- How does LSTM solve vanishing gradients?
LSTM은 vanishing/exploding gradient를 보장하지 않는다. 단지, 모델이 long-distance dependency를 학습할 수 있는 쉬운 방법을 모델에게 제공함으로서, vanishing/exploding gradient problem이 발생하지 않도록 유도할 뿐이다.
- GRU(Gated Recurrent Units)
LSTM의 개념을 유지한채 gate의 개수를 줄임으로서, LSTM의 특징을 유지하며 가벼운 모델이다.

GRU에서 update gate는 lstm의 forget gate와 input gate를 합친 역할을 하며, reset gate는 hidden state중 어느 부분을 이용할 지 결정하는 gate이다.

GRU는 lstm과 달리 cell state를 이용하지 않고 이를 hidden state를 이용해 구현함으로서, 보다 가벼운 모델을 구현할 수 있었다.
- Is vanishing/exploding gradient just a RNN problem?

vanishing/exploding gradient는 RNN외의 다른 뉴럴 아키텍쳐에서도 나타나는 문제점이며, 특히 깊이가 깊을 때 문제점으로 많이 지적된다.
다른 뉴럴 아키텍쳐에서는 직접적인 connection을 추가함으로서 vanishing/exploding gradient 문제를 해결하였다.


Conclusion: Though vanishing/exploding gradients are a general problem, RNNs are particularly unstable due to the repeated multiplication by the same weight matrix
- Bidirectional RNNs

-한쪽 방향이 아닌, 양쪽 방향의 RNN을 이용하면 좀 더 성능이 좋은 RNN 모델을 개발할 수 있다.
-Bidirectional RNN 모델 설계방법은, forward RNN과 backward RNN을 따로 학습한 뒤, 각 hidden state를 concat하여 최종적인 hidden state를 구성한다.
-하지만 Bidirectional RNN은 entire input sequence에 대한 접근이 가능할 때 사용이 가능하며, 이로 인해 Language Modeling에는 적용이 불가능하다. (Language model은 left context만 활용이 가능하므로)
-entire input sequence에 대해 접근이 가능하다면, bidirectionality는 굉장히 효과적이며, Bidirectionality를 이용한 대표적인 예가 BERT이다.
'NLP' 카테고리의 다른 글
[cs224n] Lecture 8 (1) 2021.08.07 [cs224n] Lecture 6 (0) 2021.08.07 [cs224n] Lecture 5 (0) 2021.08.07 [cs224n] Lecture 4 (0) 2021.08.07